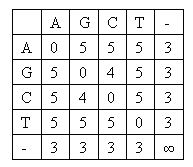
contains two lines, which are the two DNA sequences to align. DNA sequences contain only characters 'A', 'G', 'C' and 'T'. The length of each sequence is not greater than 50000.
You can assume that all the input cases are highly similar sequences.